Prepare the namespace aliases
namespace logging = boost::log;
namespace sinks = boost::log::sinks;
namespace src = boost::log::sources;
namespace expr = boost::log::expressions;
namespace attrs = boost::log::attributes;
namespace keywords = boost::log::keywords;Definitions 1
- Log record: a single bundle of info that is collected from the app and is a candidate for the log output
- Attribute: a piece of meta-info that can be used to specialize a log record e.g. ThreadID, Timestamp, etc.
- Attribute value: the actual data acquired from attributes and is attached to a specific log record. Values can have different types
- Attribute value visitation: a way of processing the attribute value, which involves applying a “visitor” (a function obj) to the attribute value
- Attribute value extraction: a way of processing the attribute value when the caller attempts to obtain a reference to the stored value. The caller should know the stored type of the attr value in order to be able to extract it
- Log sink: a target to which all log records are fed after being collected from the user’s app
- Log source: an entry point for the user’s app to put log records to
- Log filter: a predicate that takes a log record and tells whether this record should be kept or discarded
- Log formatter: a function obj that generates the final textual output from a log record
- Logging core: the global entity that maintains connections b/w sources and sinks and applies filters to records. usually used at the logging init
- TLS: thread-local storage
Architecture 2
Three-layer architecture
- Data collection layer
- (Connection layer) Central-hub that interconnects the collection and the processing layers
- Data processing layer
Visualization
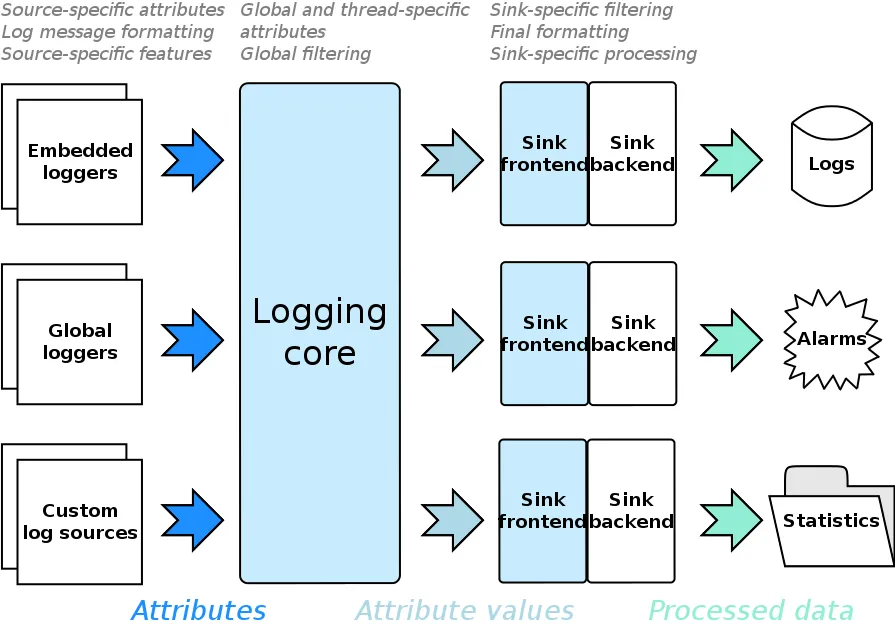
- Arrows show the info flow direction
- the left-most is our application (log sources)
- the right-most is the final storage if any
- storage is optional because the processed log may include some actions without actual data persisting
- e.g. the app can emit a special log record that will be processed s.t. the user sees the error msg as a tool-tip notification over the app icon and hears an alarming sound
- this allows boost log be used not only for classic logging, but also to indicate some important events to the app user and accumulate statistical data
Log sources
A log source is an entity that initiates logging by constructing a log record. In general, boost log lib does not require the use of loggers to write logs. But loggers are the most common kind of log sources.
In the left-most of the arch, our application emits log records with the help of loggers, which are special obj that provide streams to format msgs that will eventually be put to log
Boost log lib provides many different logger types and you can craft your own by extending the existing ones.
Loggers are designed as a mixture of distinct features s.t. they can be used in combination.
You can embed the logger into your application classes or create and use a global instance of the logger.
- Embedding a logger provides a way to differentiate logs from different instances of the class
- A single global logger instance is more convenient like in functional-style programming
Attributes and attribute values
A log source must pass all data associated with the log record to the logging core. This data is represented with a set of named attributes and each one is a function whose result is what we call “attribute values”. The attribute values are processed on further stages.
An example attribute is a function that returns the current timestamp, and its result (i.e. its value) is the particular time point.
We can classify attributes into 3 categories, ordered by increasing priority:
- Global attributes
- Thread-specific attributes
- Source-specific attributes
The global and thread-specific attributes are maintained by the logging core, as shown in the architecture figure, and therefore these attributes need not be passed by the log source in order to initiate logging.
The global attributes are attached to any log record ever made.
Thread-specific attributes are attached only to the records made from the thread in which they were registered in the set.
Source-specific attributes are maintained by the source that initiates logging, and attached only to the records being made through that particular source.
When a log source initiates logging, it acquire attribute values from all three attribute sets. These values form a single set of named attribute values, and is then processed further.
It’s possible that a same-named attribute that appear in several attribute sets. Such conflicts are solved on priority basis. The global attributes have the least priority and the source-specific attributes have the highest.
Logging core and filtering
Filtering: After the logging source composed the named attribute values set, the logging core decides if this log record is going to be processed in sinks.
Two layers of filtering:
- Global filtering is applied first within the logging core and allows quickly wiping away unneeded log records
- Sink-specific filtering is applied second within each sink separately and allows directing log records to particular sinks.
It is not significant where the log record comes from (i.e. regardless the logging source that emit them), the filtering relies solely on the set of named attribute values attached to the record.
For a given log record, the filtering is performed only once and only those attribute values that are attached to the record before the filtering starts can participate in filtering. We say this because some named attribute values, like the “log record message”, are typically attached to the log record after the filtering is done, which means these values cannot be used in filters!
Sinks and formatting
A log record that passes filtering for at least one sink is considered as consumable.
If the sink supports formatted output, this is the point when log msg formatting takes place. Note that formatting is done on a per-sink basis s.t. each sink can have its own specific output format.
The formatted msg along with the composed set of named attribute values are passed to the accepting sinks.
As shown in the arch figure, a sink consists of two parts:
- Sink frontend
- Sink backend
The division is made to extract the common functionality of sinks like filtering, formatting, thread sync into separate entities (frontends).
Sink frontends are provided by the lib and usually users won’t have to reimplement them. Sink backends are one of the most likely places for extending the library. The backends do the actual data processing.
There can be multiple sinks in a single app.
E.g.
- a sink that stores processed log records into a file
- another sink that sends the processed log records over the network to the remote log processing node
- another sink that puts record msgs into tool-tip notifications
The lib also provides most commonly used sink backends.
Tutorial 3
Trivial logging
Necessary headers:
#include <boost/log/trivial.hpp>The BOOST_LOG_TRIVIAL macro accepts a severity level and results in a stream-like objects that support insertion operator. The log msg will be printed on the console.
E.g.
#include <boost/log/trivial.hpp>
int main(int, char*[])
{
BOOST_LOG_TRIVIAL(trace) << "A trace severity message";
BOOST_LOG_TRIVIAL(debug) << "A debug severity message";
return 0;
}Features:
- Each log record in the output msg contains a timestamp, a thread ID and the severity level
- It is safe to write logs from multiple threads concurrently and log msgs will not be corrupted
- Filtering can be applied
Add filters to the trivial logging
You will normally want to apply filters to output only significant records and ignore the rest.
Let’s do this by setting a global filter in the logging core.
void init()
{
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}
int main(int, char*[])
{
init();
BOOST_LOG_TRIVIAL(trace) << "A trace severity message will be ignored";
BOOST_LOG_TRIVIAL(debug) << "A debug severity message will be ignored";
BOOST_LOG_TRIVIAL(info) << "An informational severity message";
return 0;
}Since we are setting up a global filter, we have to acquire the logging core instance using logging::core::get(). It returns a pointer to the core singleton instance.
The filter in this example is built as a Boost.Phoenix lambda expression. The left argument is a placeholder that describes the attribute to be checked. The placeholder along with the ordering operator creates a function object that will be called by the logging core to filter log records and only records that pass the predicate will end up on the console.
Setting up sinks
The lib contains a default sink that is used as a fallback when the user did not set up any sinks. This is why our previous trivial logging example worked. This default sink always print log records to the console in a fixed format and is mostly provided to allow trivial logging to be used right away.
Sometimes trivial logging does not provide enough flexibility like when one wants to apply complex log processing logic. You need to construct logging sinks and register them with the logging core in order to customize this. This only needs to be done once somewhere in the startup code.
Note that once you add any sinks to the logging core, the default sink will no longer be used! You will still be able to use trivial logging macros though.
Logging to files
E.g.
void init()
{
logging::add_file_log("sample.log");
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}The add_file_log function initializes a logging sink that stores log records into a text file. You can also customize it with additional parameters in a named form:
logging::add_file_log
(
keywords::file_name = "sample_%N.log", // file name pattern
keywords::rotation_size = 10 * 1024 * 1024, // rotate files every 10 MiB
keywords::time_based_rotation = sinks::file::rotation_at_time_point(0, 0, 0), // or at midnight
keywords::format = "[%TimeStamp%]: %Message%" // log record format
);Creating loggers and writing logs
The logger object is a logging source that can be used to emit logs records.
The trivial logging example we seen above uses the logger provided by the lib and is used behind the scenes through the macro.
Unlike sinks, logging sources (loggers) need not be registered since they interact with the logging core directly.
Boost log lib provides two types of loggers:
- Thread-safe loggers
- Non-thread-safe loggers
It is safe for different threads to write logs through different instances of the non-thread-safe logger, which means a separate logger for each thread to write logs.
The thread-safe logger can be accessed from different threads concurrently and the thread-safety is protected by using locks, which means worse performance incase of intense logging compared to the non-thread-safe counterparts.
Regardless of the thread safety, all lib-provided loggers are default and copy-constructible and support swapping, so there should be no problem in making a logger a member of your class.
The lib provides many loggers with different features, such as severity and channel support. These features can be combined with each other in order to construct more complex loggers.
Global logger object
In case you cannot put a logger into your class (suppose you don’t have one), the library provides a way of declaring global loggers like this:
// Remember that we defined namespace src = boost::log::sources;
BOOST_LOG_INLINE_GLOBAL_LOGGER_DEFAULT(my_logger, src::logger_mt)The my_logger is a user-defined tag name that will be used later to retrieve the global logger object.
The logger_mt is the logger type. Any logger type provided by the lib or defined by the user can participate in such declaration. But note that you will normally want to use thread-safe loggers in a multi-threaded app as global logger obj since the logger will have a single instance.
In other parts of your app, you can acquire the global logger like this:
src::logger_mt& lg = my_logger::get();The lg will refer to the one and only instance of the global logger throughout the application. The get function is thread-safe and hence you don’t need additional synchronization around it.
Writing logs
E.g.
logging::record rec = lg.open_record();
if (rec)
{
logging::record_ostream strm(rec);
strm << "Hello, World!";
strm.flush();
lg.push_record(boost::move(rec));
}The open_record function determines if the record to be constructed is going to be consumed by at least one sink, i.e. filtering is applied at this stage.
If the record is to be consumed, the function returns a valid record obj and we can then fill the record msg into it. The record processing can be completed with the call to push_record.
It seems complicated to use the logger even for the most simple log message… But we can easily wrap them into a macro! The log record above can be written like this:
BOOST_LOG(lg) << "Hello, World!";The BOOST_LOG macro, along with other similar ones, is defined by the library.
Adding more info to log with Attributes
As said above, each log record can have many named attribute values attached. Attributes contain essential information about the log emit condition, like the line number in the code, executable name, current time, etc.
An attribute may behave as a value generator, i.e. it may return a different value for each log record it is involved in. As soon as the attribute generates the value, the value becomes independent from the creator and can be used by filters, formatters and sinks.
In order to properly use attributes in your code, you need to know its name and type (or at least a set of types it may have).
As discussed in the previous sections, attributes can be classified into 3 scopes: global, thread-specific, and source-specific. When a log record is made, attribute values from these 3 sets are joined into a single set and passed to sinks. This implies that the origin of the attribute makes no difference for sinks!
Any attribute can be registered in any scope. An attribute is given a unique name upon registration in order to make it possible to search for it. As mentioned earlier, conflicts resolution is based on priority.
Attribute registration
There are common attributes that are likely to be used in nearly any application.
Here we take the log record counter attribute and the timestamp attribute for example. Such commonly used attributes can be registered with a single function call:
logging::add_common_attributes();Common attributes like “LineID”, “Timestamp”, “ProcessID”, and “ThreadID” are registered globally.
Some special attributes are registered automatically for you on logger construction.
E.g. the severity_logger registers a source-specific attribute “Severity” which can be used to add a level of emphasis for different log records.
The BOOST_LOG_SEV macro acts pretty much like BOOST_LOG except that it takes an additional argument for the open_record method of the logger.
Usually we want to register a named_scope attribute so that we can store scope names in log for every log record.
E.g.
// some where in logger init
core->add_global_attribute("Scope", attrs::named_scope());
...
// some where in usage
void named_scope_logging()
{
BOOST_LOG_NAMED_SCOPE("named_scope_logging");
src::severity_logger< severity_level > slg;
BOOST_LOG_SEV(slg, normal) << "Hello from the function named_scope_logging!";
}Another useful attribute for performance analysis is what we call the “Timeline” attribute.
After registered the “Timeline” attribute e.g. through BOOST_LOG_SCOPED_THREAD_ATTR("Timeline", attrs::timer());, every log record after this will contain the “Timeline” attribute with a high precision time duration passed since the attribute was registered.
Based on these readings, one will be able to detect which parts of the code require more or less time to execute. This attribute will be unregistered upon leaving the scope that defined it.
Log record formatting
After adding/registering attributes, you need to specify a formatter that will use these attribute values in order to have them reach the output.
As we have seen in the tutorial about writing logs to files, we defined a formatter that used the “TimeStamp” and “Message” attributes.
void init()
{
logging::add_file_log
(
keywords::file_name = "sample_%N.log",
keywords::rotation_size = 10 * 1024 * 1024,
keywords::time_based_rotation = sinks::file::rotation_at_time_point(0, 0, 0),
keywords::format = "[%TimeStamp%]: %Message%"
);
logging::core::get()->set_filter
(
logging::trivial::severity >= logging::trivial::info
);
}The format parameter allows us to specify the format of the log record. If you want to set up sinks manually, you can achieve this by using the set_formatter member function of the sink frontends.
Lambda-style formatters
E.g.
keywords::format =
(
expr::stream
<< expr::attr< unsigned int >("LineID")
<< ": <" << logging::trivial::severity
<< "> " << expr::smessage
)The stream is a placeholder for the stream to format the record in. The insertion arguments like attr and message are manipulators that define what should be stored in the stream. Note that it is possible to replace severity with the following expr::attr< logging::trivial::severity_level >("Severity").
It is recommended to define placeholders like severity for user’s attributes since it provides simpler syntax in the template expressions and makes coding less error-prone.
Boost.Format-style formatters
E.g.
sink->set_formatter
(
expr::format("%1%: <%2%> %3%")
% expr::attr< unsigned int >("LineID")
% logging::trivial::severity
% expr::smessage
);The format placeholder accepts the format string like printf with positional specs of all arguments being formatted.
Note that only positional format is currently supported, which means you cannot have all features in the Boost.Format.
When you call format(s) where s is the format-string, it constructs an obj that parses the format string and looks for all directives in it and prepares internal structures for the next step.
Then you feed variables into the formatter.
Once all args have been fed you can dump the format obj to a stream.
All in all, the format class translates a format-string into operations on an internal stream, and finally returns the result of the formatting as a string or directly into an output stream.
Specialized formatters
These specialized formatters are designed for a number of special types like date, time, named scope. They provide extended control over the formatted values.
E.g. You can describe date and time format with a format string compatible with Boost.DateTime
expr::stream
<< expr::format_date_time< boost::posix_time::ptime >("TimeStamp", "%Y-%m-%d %H:%M:%S")
<< ": <" << logging::trivial::severity
<< "> " << expr::smessageString templates as formatters
In some contexts, textual templates are accepted as formatters and the lib init support code is invoked to parse the template and reconstruct the appropriate formatter.
It’s suitable for simple formatting needs but keep in mind when using this approach there are a number of caveats and you should be careful if you want to use it in a complex formatting need.
E.g.
keywords::format = "[%TimeStamp%]: %Message%"The format now accepts a format string template that contain a number of placeholders enclosed with percent signs. Each placeholder contain an attribute value name to insert instead of the placeholder.
Note that such format templates are not accepted by sink backends in the set_formatter method! You need to call parse_formatter to parse textual template into a formatter function!
Custom formatting functions
You can add a custom formatter to a sink backend that supports formatting. The formatter is actually a function obj that supports the following signature:
// CharT is the target character type
void (logging::record_view const& rec, logging::basic_formatting_ostream< CharT >& strm);The formatter will be invoked whenever a log record view rec passes filtering and is to be stored in the log.
I tried to customize the ThreadID attribute with the lambda style formatter but got no luck, FYI here’s a pretty old discussion about formatting ThreadID.